11.03.2024
Большинство сотрудников Mediascope используют Python для решения повседневных задач: разрабатывают модели машинного обучения, пишут код для веб-сервисов, анализируют данные, автоматизируют рутинные процессы. В прошлом году мы провели корпоративный чемпионат, который помог повысить мотивацию к изучению Python и оживить внутреннее комьюнити. А ещё чемпионат получил продолжение: модель из ML-трека стала прототипом во внутреннем конвейере обработки данных. Рассказываем в новой статье на Хабр, как это было.
Python как корпоративный эсперанто
Python в Mediascope применяют не только разработчики. С 2019 года мы обучаем работе с ним аналитиков и социологов, для того чтобы они больше и чаще использовали Jupyter-ноутбуки в работе с данными Big Data платформы. Этот язык программирования стал универсальным языком кросс-командного взаимодействия — чем-то вроде корпоративного эсперанто, на котором сотрудники могут обмениваться идеями, результатами анализа и приходить друг к другу за помощью в решении сложных задач.
Число питонистов в Mediascope растёт, и чтобы поддерживать высокий уровень знания Python, мы организуем для них больше активностей. Создали внутренний курс, который вызвал большой отклик: обучили уже четыре потока сотрудников, всего более 100 человек. Устраиваем регулярные митапы, а в прошлом году провели чемпионат.
Подготовка к чемпионату
Желание провести корпоративный чемпионат подогревала мысль, что это оживит внутреннее комьюнити без привязки к продуктовым задачам и поддержит сплочённость коллектива: в нашей компании распределённая команда, есть офисы в Москве и Туле, многие сотрудники работают на удалёнке из разных городов. Хотя работаем мы слаженно, из-за специфики дистанта не всегда ощущаешь плечо товарища, а соревнование как форма тимбилдинга добавляет положительных эмоций в общение.
Первым делом собрали инициативную группу, в которую вошли несколько IT-лидов, а также сотрудники HR-отдела и внутренних коммуникаций. Для освещения чемпионата создали страницу на корпоративном портале, а дополнительно оповещали сотрудников об основных этапах соревнования с помощью рассылки по электронной почте. Бюджет, выделенный на чемпионат, направили на закупку призов для победителей.
Платформа для участников
Чемпионат проходил в онлайн-формате. Для его проведения мы создали собственную платформу.
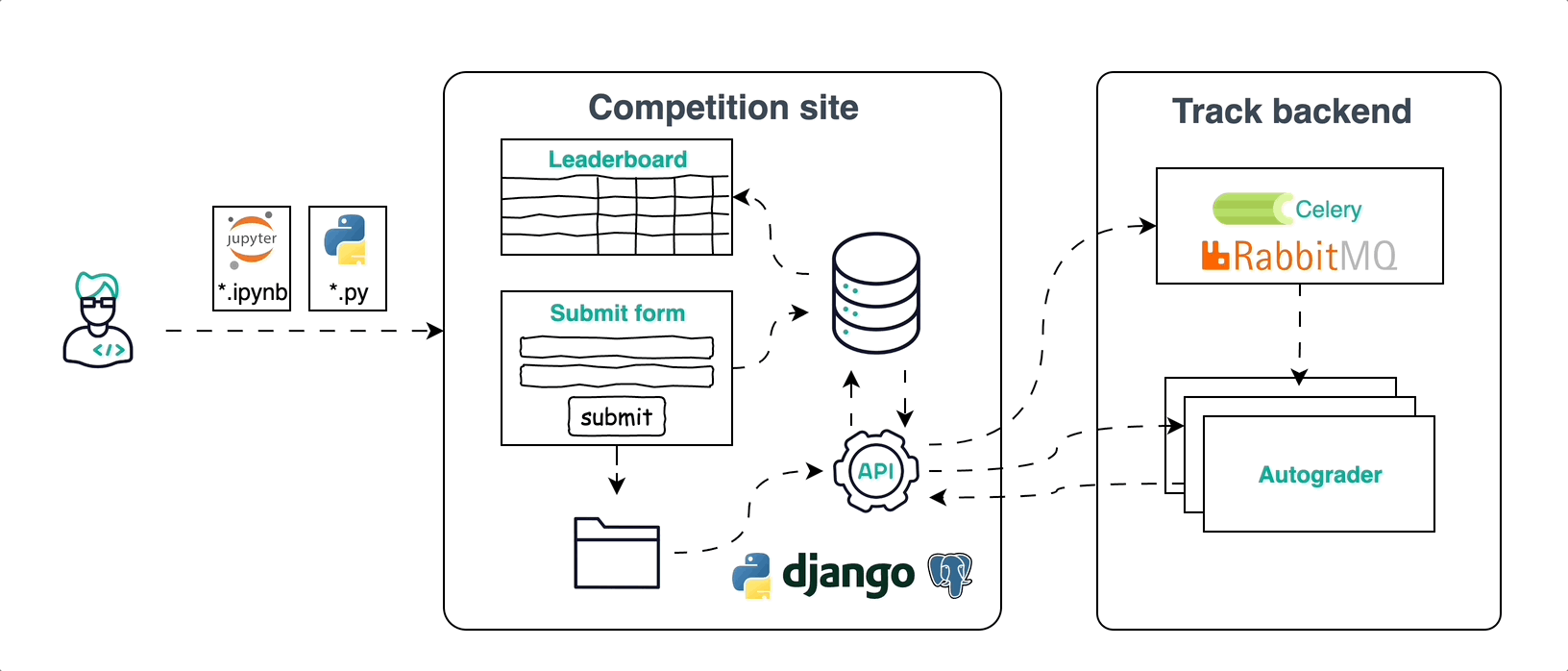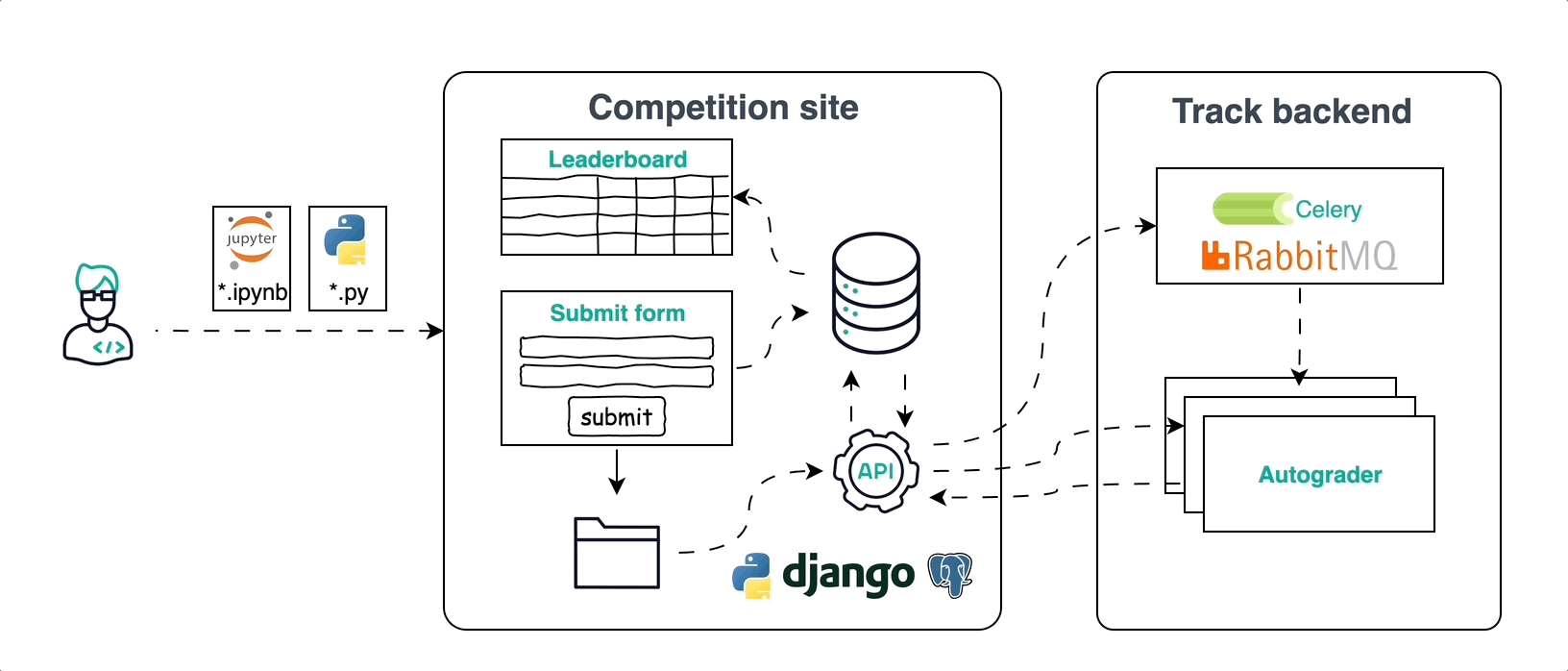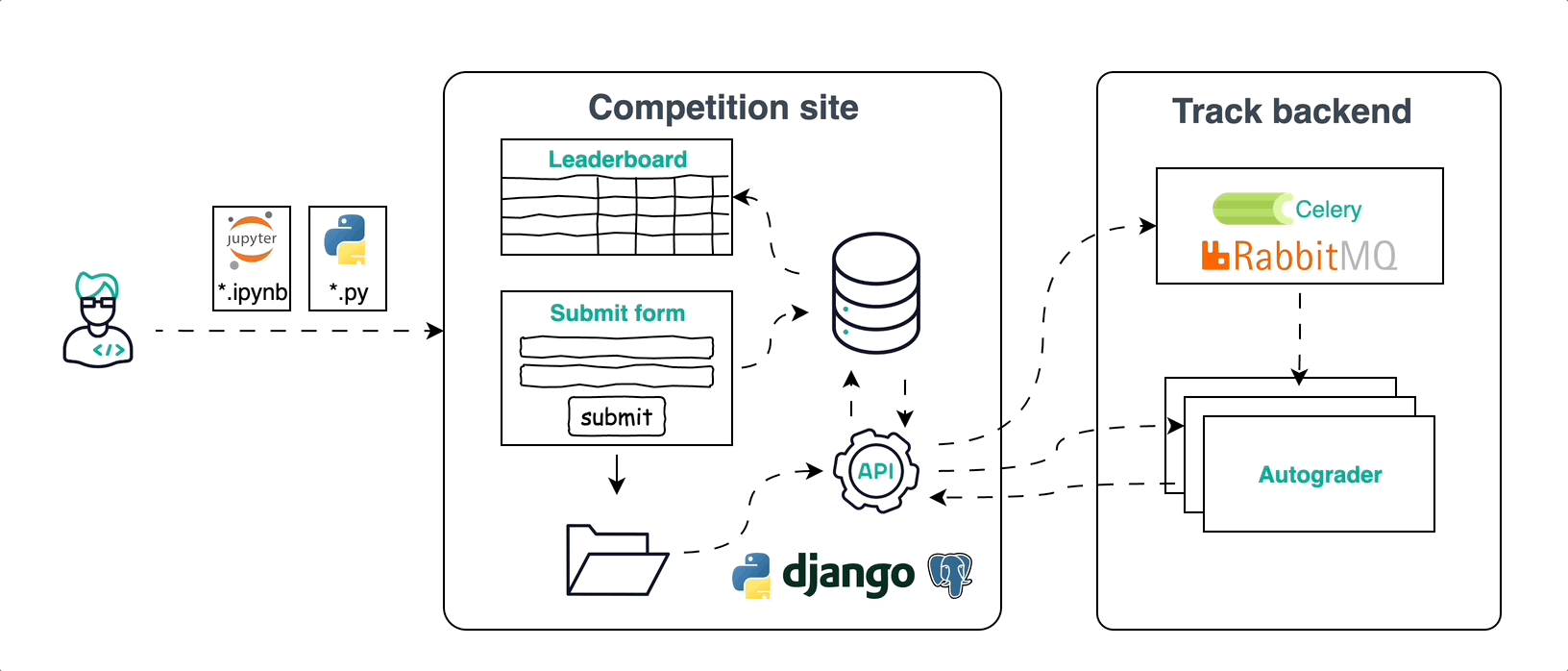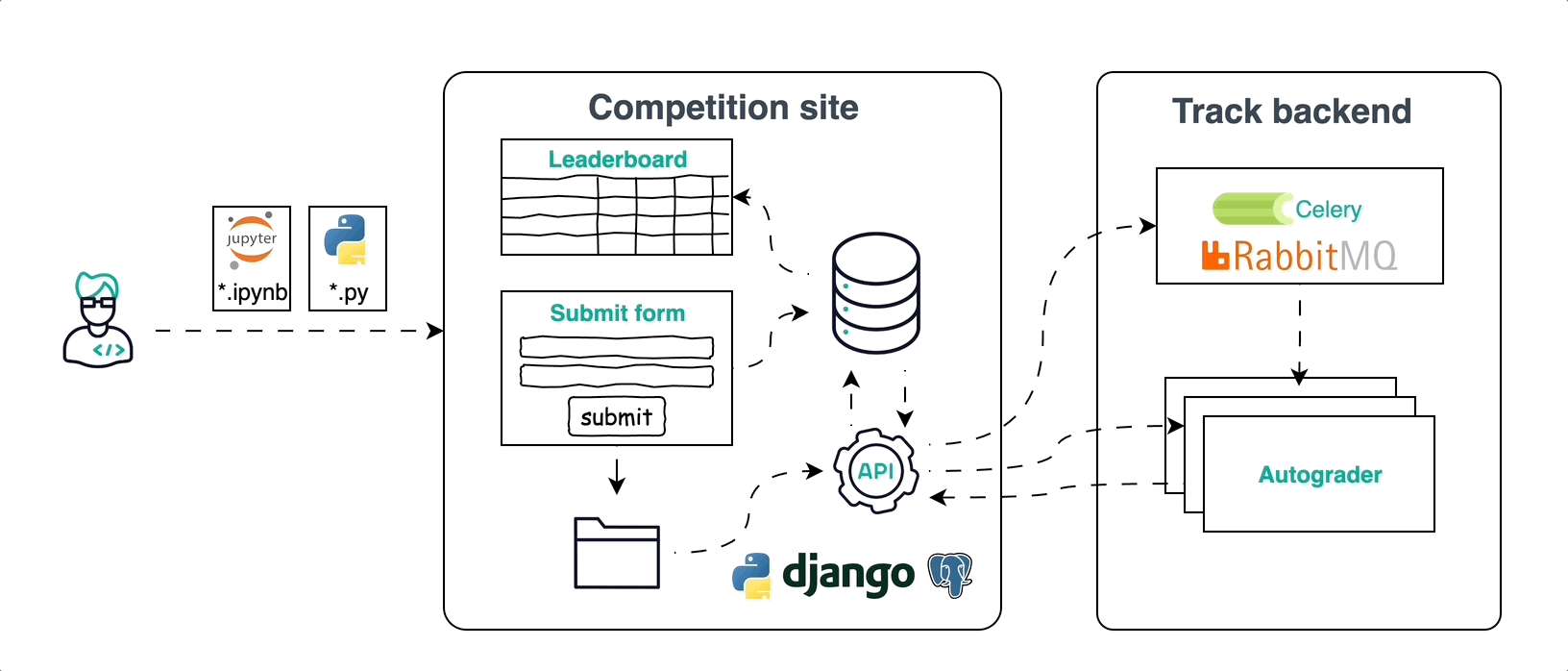
Сначала были попытки использовать существующие open-source решения, но ни одно из них не подходило нам без значительной доработки. Дело в том, что в нашем соревновании использовались не только стандартные метрики машинного обучения, и решения участников проверяли с помощью скрипта. Делать это вручную не хотелось, поэтому своя платформа оказалась оптимальным выходом. В свободное от основной работы время ребята из инициативной группы написали сайт на Django, а для расчёта метрик качества использовали скрипты-autograder’ы на Python в связке с Celery.
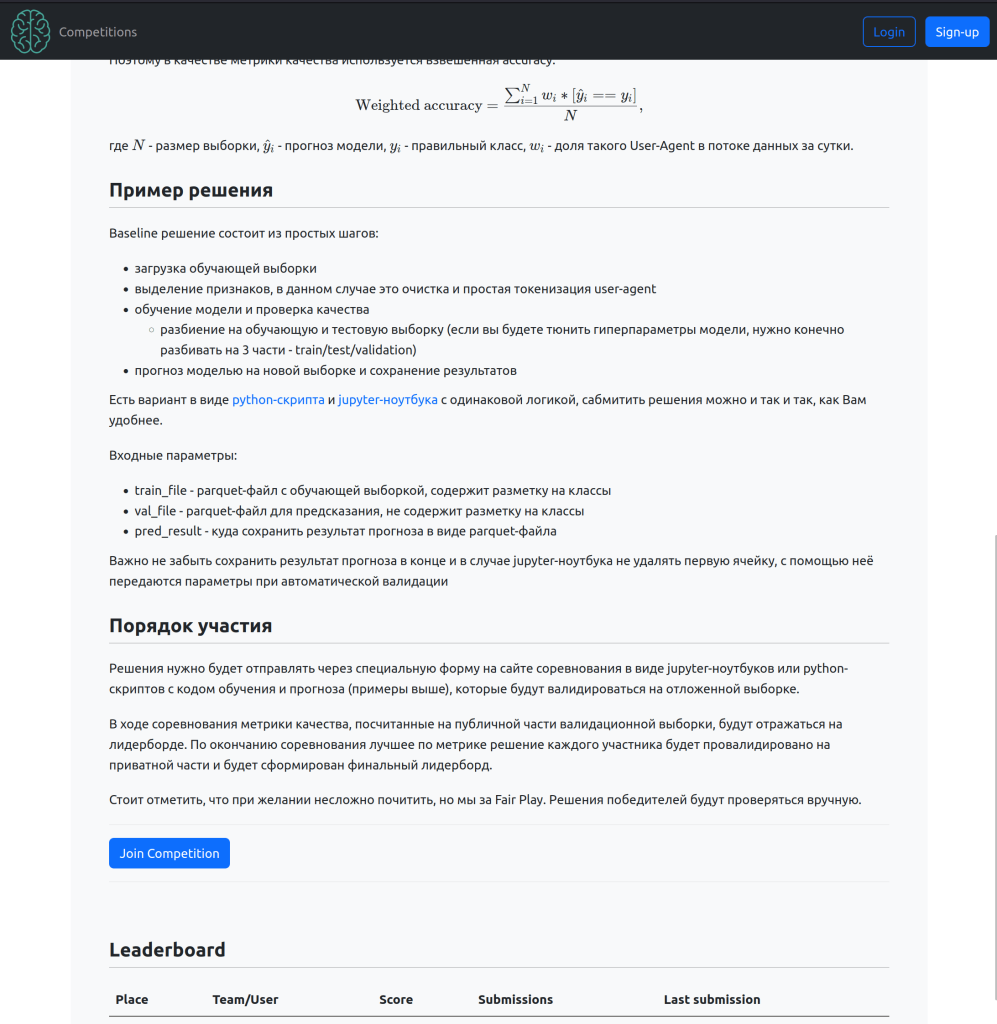
На нашей платформе мы создали специальный раздел, в котором можно было ознакомиться с содержанием треков и скачать baseline-решения, шаблоны которых подготовили в виде Jupyter-ноутбука и Python-скрипта. В них участники заменяли логику основной функции на собственную и отправляли свой вариант на оценку. Также на платформе можно было посмотреть автоматический лидерборд в стиле Kaggle, который обновлялся при загрузке очередного ответа: в ходе соревнования участникам были доступны метрики по публичной части валидационной выборки, а когда соревнование закончилось и уже никто не мог повлиять на своё решение, открывался приватный лидерборд.
В выборе никнейма дали свободу, чтобы при желании можно было участвовать анонимно. Для общения на чемпионате предусмотрели чат с организаторами и участниками.
А теперь про разработку треков
Подготовка заданий стала вызовом. Мы хотели, чтобы в чемпионате поучаствовало как можно больше сотрудников с разным уровнем Python — от продуктовых аналитиков до системных администраторов и специалистов по информационной безопасности. Задачи нужны были достаточно сложные, чтобы привлечь интерес, но все же решаемые, чтобы не отбить желание к участию. Оказалось, что соблюсти этот баланс не так просто, но в итоге было разработано три конкурсных трека.
- ML-трек по определению типа устройства.
Мы предложили участникам решить задачу классификации типа устройства по строке User-Agent, передаваемой им в заголовке HTTP-запроса. Обучающую выборку из нескольких миллионов различных User-Agent взяли из реальных данных нашего счётчика.

Как это полагается при организации ML-соревнований, мы подготовили датасет, аккуратно разбили его на обучающую, публичную и приватную валидационные части и сделали простое, но эффективное baseline-решение.
Частота встречаемости отдельных строк имеет экспоненциальное распределение с большим хвостом: это учитывалось при выборе метрики качества. Была выбрана взвешенная на частоту встречаемости точность, чтобы мы могли понимать, какой процент реального потока данных от счётчика классифицирован корректно.
Для того чтобы проверить, насколько модель сохранит свою обобщающую способность на длительном периоде времени, приватная валидационная выборка была взята из данных на полтора года позже обучающей. Публичная валидационная выборка бралась за тот же период, что и обучающая, что исключало возможность подбора параметров модели под точность на валидационной выборке.
При выборе алгоритма участники пользовались полной свободой, были вольны использовать любые методы, начиная от простых эвристических правил на основе встречаемости подстрок или регулярных выражений и заканчивая моделями машинного обучения на основе логистической регрессии, «деревянными моделями», бустингом и нейронными сетями.
- Алгоритмический трек на оптимизацию сортировки.
В треке, посвящённом структурам данных и алгоритмам, участникам нужно было отсортировать большую числовую последовательность, минимизируя потребление оперативной памяти и время работы. Решение предлагалось написать на чистом Python, с использованием только встроенных в язык возможностей. Успешность алгоритма оценивалась по формуле, учитывающей время работы и объём потребляемой памяти, чем они меньше, тем лучше было для оценки. Приоритет отдавался объёму памяти, но при этом хотелось защититься от экономных, но медленных решений.
- Криптографический трек по дешифровке текста.
На десерт — атмосфера кладов и приключений из детективов «Золотой жук» и «Пляшущие человечки». Герои книг искали спрятанные сокровища и следы преступника с помощью дешифрования, а мы предложили участникам пойти по стопам этих персонажей, вооружившись Python. К примеру, как и герой Эдгара По, наши участники разгадывали шифр, подсчитывая знаки шифра и сопоставляя их с частотностью использования букв в алфавитах разных языков. С учётом того, что в компании работают не профессиональные криптографы, мы ограничились наиболее известными и простыми шифрами.
Здесь успешность измерялась количеством шифров, которые удалось взломать участнику. При этом сложность с каждым шифром возрастала.
Участники отправляли свои решения в форме Jupyter-ноутбуков или Python-скриптов, и процесс вычисления метрик происходил автоматически. В финале соревнования организаторы с интересом изучили скрипты победителей.
Битвы за сотые процента
Соперничество вышло жарким. Участники треков по машинному обучению и сортировке шли с близкими показателям по метрикам качества и буквально дышали в спину друг другу. Каждый раз, когда кто-то наступал на пятки, нужно было придумывать, как улучшить решение, что добавляло соревнованию азарта. В свою очередь трек по дешифровке заставил поломать голову, что подогревало общий эмоциональный накал. Подходы к решению задач участники представили на итоговом онлайн-митапе.
Больше всего интересных деталей нас ожидало в треке по определению типа устройства.
Один из любопытных моментов заключался в том, что эвристические решения показали хорошие результаты. Выяснилось, что если выбирать для каждой строки токен, минимизирующий энтропию распределения по классам и его наиболее частый класс в качестве прогноза, то такой подход превзойдёт baseline-метод машинного обучения.
Примечательно и то, что в этом треке победило обычное решающее дерево, хотя оно известно своей склонностью к переобучению и в современном мире практически полностью вытеснено ансамблевыми методами — случайным лесом и градиентным бустингом. Именно эта модель показала себя лучше всех как на публичном лидерборде, так и на его приватной части, то есть сохраняла обучающую способность на протяжении длительного времени лучше, чем все остальные модели.
Метрика победившего в ML-треке решения составляла 98,4% и, на первый взгляд, сопоставима с baseline, точность которого достигала 93,9%. При такой высокой точности удобнее смотреть на долю неверно классифицированных образцов. Она у победившей модели 1.6% против 6.1% у baseline, то есть победившая модель ошибается реже почти в 4 раза. Более, чем ощутимо, особенно на большом потоке данных.
В итоге бэклог команды Data Science попал проект сервиса классификации типов устройств. Поскольку соревнование было code-based, лучшие решения из чемпионата были быстро переиспользованы в качестве первой версии алгоритма.
В ходе работы над проектом случайный лес дотюнили, чтобы его результат был лучше, чем у отдельного решающего дерева. Однако в таком варианте алгоритм работал долго и потреблял много ресурсов — от использования этой модели в качестве production-решения отказались в пользу линейной модели, которая с небольшим отставанием заняла второе место. После доработки она уступала решающему дереву по метрикам очень несущественно, но при этом работала быстрее и её оценки вероятности принадлежности к классам лучше подходили для отбора образцов, в которых модель не уверена, на доразметку.
При внедрении одним из требований к модели была необходимость работы в потоке обработки данных счётчика под высокой нагрузкой, в качестве решения выбрали реализовать инференс на Java, и коллеги из разработки портировали туда код препроцессинга данных и инференса обученной моделью. Это позволило достичь необходимых требований по скорости его работы. Интересно, что так как прототип модели был взят из скрипта с конкурсным решением, то в конфигурационный файл сервиса он так и перекочевал с названием по имени участника: vlad_model.
В финале немного цифр о чемпионате
- 4 месяца подготовки,
- 8 сотрудников в инициативной группе,
- 3 конкурсных трека,
- 1,5 месяца на реализацию решений,
- 35 участников из разных подразделений компании,
- 7 победителей,
- 416 сабмитов на финише проекта, из них 322 успешных.
Когда мы начинали подготовку, то не ожидали большой вовлечённости, и рады, что участники активно соревновались за лидерство в топе. Надеемся проводить такие чемпионаты на регулярной основе, чтобы попробовать другие задачи и подходы — идеи ещё не кончились.
Контакты пресс-службы
- Ирина Шпунтова
Руководитель PR-службы - +7 (495) 935-87-18